
背景
在前面的文章里,已经使用智谱清言的智能体实现了一个翻译机器人,考虑到智能体囿于系统提供的能力,有些设置可能通过编程控制会更容易。那么实际情况是否如此呢?我最近直接调用 GLM-4 的 restapi 尝试了一下。
实际上我的目的不仅仅是需要一个智能翻译助手。这个目标我的智能体应用已经基本可以满足了。我还想体验一下目前比较主流的大模型,能不能真正的实现一些应用功能。
就以我的体验来说,GLM-4 在指令遵循方面,还是有些问题,另外,响应时间是大模型的死穴。
下一步,我会考虑接入阿里的通义千问,百度的 ERNIE-Bot,体验下其他大模型的理解能力,指令遵循能力。
讯飞星火暂时不考虑,上次看过文档,他们家的 api 只能使用 ws/wss 协议,编程控制有点麻烦。
角色
在使用智能体时,我只能通过预先设置的配置来控制智能体,无法干预用户的输入。
那么在使用 restapi 时,这就不是问题了,我既可以像智能体配置一样预先定义规则,也可以实时的修改用户的输入。
这个能力,是因为大模型给我们提供了“角色”这样的概念。
发送给大模型的内容,可以区分角色,一般来说,实际和大模型对话的用户,其角色是 user
而大模型自身,我们可以用一个 system 角色来定义它,让大模型知道自己在这次对话里承担什么职责,遵守什么规则。
比如,一个翻译机器人,用户输入的是 "show me the money",那么我们发送给大模型的数据大概类似下面的样子
{
messages:[
{role:"system", content:"你是个翻译机器人,你翻译并提取知识点讲解"}
{role:"user", content:"show me the money"},
]
}我感觉,在创建智能体时,我的配置实际上是 system 这个角色的配置。现在通过编程来实现,我就可以修改用户的输入,还是上面的例子,可以如下修改
{
messages:[
{role:"system", content:"你是个翻译机器人,你翻译并提取知识点讲解"}
{role:"user", content:"翻译以下内容:`show me the money`"},
]
}很显然,这样就可以大幅简化 system 里的规则。
另外,智能体是默认支持多轮对话的,也就是说,虽然翻译的内容互相之间理应没有关联,但是智能体每次翻译,都会自动将你历史轮次的原文和译文传递给大模型,这既导致翻译比较慢,也会干扰大模型的行为。
使用编程控制后,就可以不传递历史数据给大模型,提升了大模型的响应时间,也简化了规则设计。
不过,编程控制也有其难处。
编程的难点
要编程实现一个翻译机器人,需要考虑以下几点
- 机器人如何访问?
- 大模型如何返回格式化的数据?
关于机器人如何访问,我实现了 2 种访问模式
- 通过网页访问:在我的个人主页做了一个网页,可以和翻译机器人对话
- 通过企业微信访问:我注册了企业微信,当然我不是企业,这个企业微信无法认证。但是未认证企业也可以开发企业微信应用,在企业微信里,可以和这个应用对话
让大模型返回格式化的数据
这个还是很有难度的。最理想的是让大模型返回 json 格式。
但是大模型不是一个机器,人家是 AI,是有“智慧”的,你要它返回 json,它就返回 json?那和机器有什么区别~!
我把 prompt 改了很多遍,但是没有办法,GLM-4 不能保证给我返回 json,有时候它返回的是 markdown 格式的 json,如下
```json
{
"lang":"English",
"translation":"...",
}
```
好消息是大多数时候,它的返回要么是 json,要么是 markdown 格式的 json,程序针对性的解析还是可以的。
另外一个问题是,它返回的 json 格式不标准。常见的是换行符没有被转义。这样的 json,不管哪种语言的 json 库都无法解析。
不过经过我对 prompt 的反复优化,这个错误出现的频率不高。
另外,大模型倾向于返回“漂亮的” json,也就是缩进过的 json,比较易读,但是我这是程序处理,你返回那么多缩进,还消耗了我的 token。不过这个问题也很难优化,如果你给他指令,返回压缩的 json,它可能就忘记了对换行进行转义。
响应慢
我以前做过广告竞价,广告的 CTR 也是通过算法预估的,我们一般要求算法在 400 毫秒内返回预估的 CTR,实际上正常情况下是 100 毫秒内返回的。
但是大模型做翻译,响应时间是秒这个数量级,实在太慢了。要用于一般应用场景,我感觉不是太行。
这个响应慢可以说是大模型天生的属性,如果不能解决,很多场景大模型都不适合介入。
体验
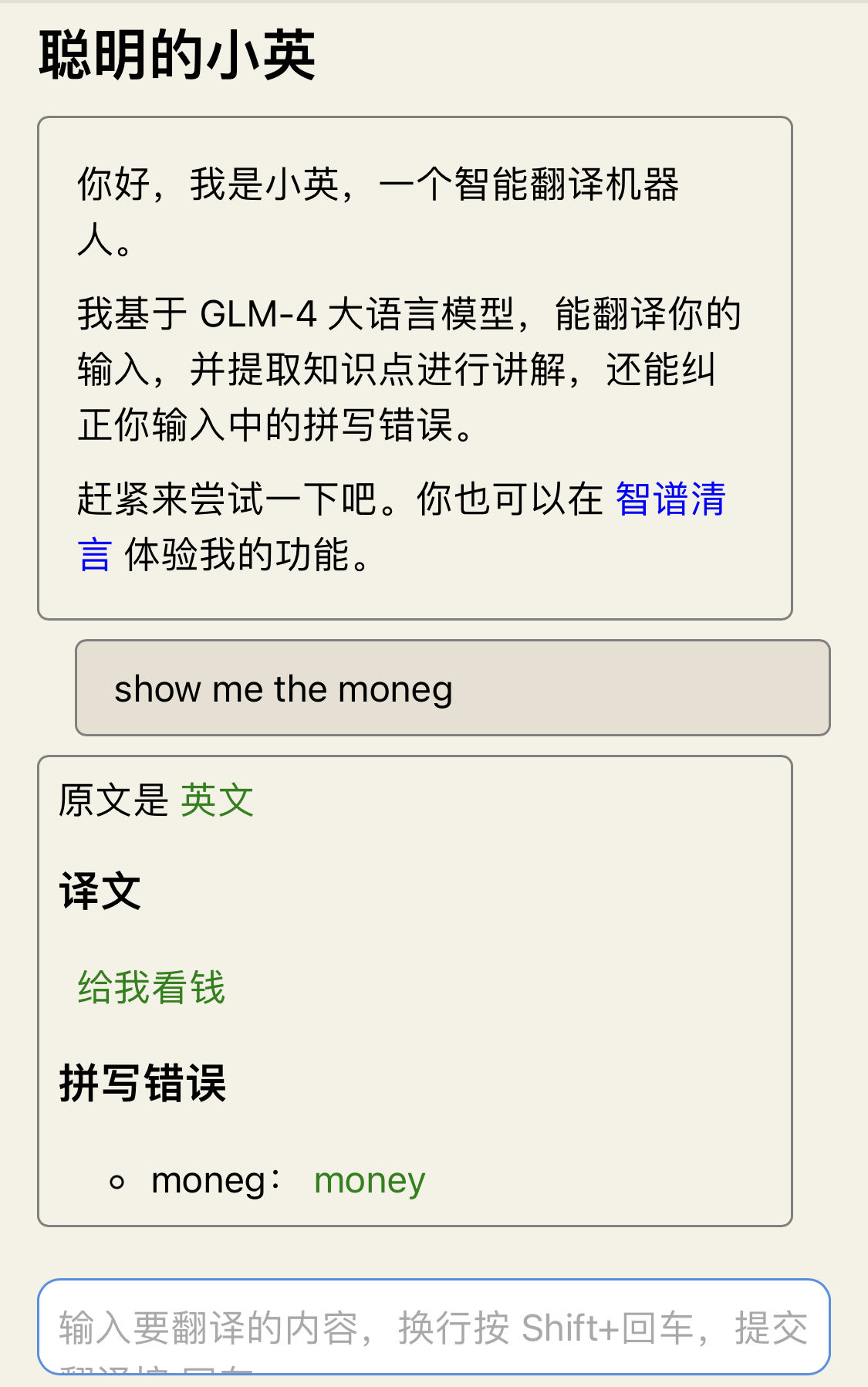
网页版小英
企微版小英
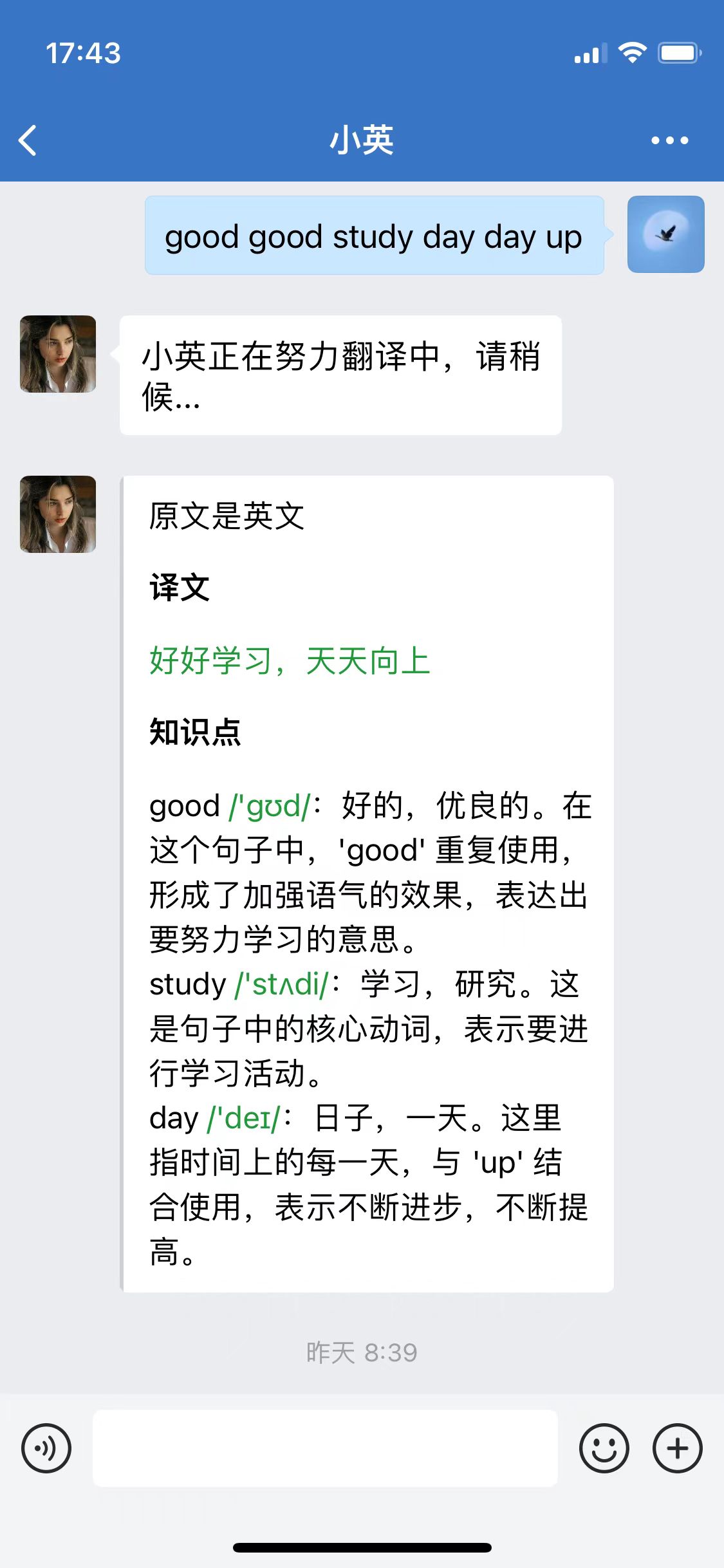
因为大模型响应较慢,所以在企微里,采用了异步对话的机制,先立即回复一个“翻译中”,等大模型返回结果后,再发送结果。
写在最后的话
首先是对 GLM-4 进行一个评估
- 响应慢,请提升算力
- 指令遵循度不够。返回个 json 这么个简单要求,无法完美实现。程序接入这样的场景,返回格式化数据是基本要求。如果做不到,大模型终究只能和人聊天罢了。人可以理解你的输出,程序能理解吗?
关于角色的一点想法
大模型诞生之初,并没有角色这个概念。是在使用中,用户发现,如果在 prompt 里给大模型设定一个角色,大模型能更好的工作。之后,openai 才在 api 里提供了角色支持。
比如我这个翻译机器人,system 的内容,写到 user 里不行吗?我相信对于大模型来说,应该没有影响。
不过,这样实际上污染了用户数据,我们很难在 prompt 里区分出哪些是用户的原始输入,哪些是我们给大模型的角色定义和规则。
所以,GLM-4 智能体根本就不开放修改用户输入的能力。对于程序开发者来说,需要在这之间取一个平衡:尽量不要修改用户的原始输入,而是通过 system 的 prompt 来约束大模型的行为,除非对用户输入的修改能够大大简化 prompt 的设计。
