
背景
互联网后台的性能问题,一般表现为内存不足、响应变慢,导致前端出现大量超时甚至 5xx 错误,这里分享一个我做应用商店后台时解决的性能问题实例
当时的表现是我们的监控系统会频繁发出内存相关的告警,甚至不在业务高峰期也会告警,主要是下面 2 种情况
-
可用内存不足,如下
Item : Available Memory Value : 159.36 MB IP : 10.161.4.158 -
虚拟内存占用过多,如下
Item : Swap used > 60 Value : 62.6 % IP : 10.161.4.99
优化思路
后台从业者最头疼的大概就是性能问题了,一般来说性能问题是个系统性的问题,要追根溯源的话,至少要从设计阶段开始,对于一个有一定规模的业务系统,性能不足很难定位到某个确定的点。
理想的情况当然是通过 jmap,jstack 之类的调优工具定位到代码中的某一行,不过在运维帮忙 dump 过几次内存快照、线程堆栈后,并没有分析出什么原因来
性能优化没有银弹,我默默安慰自己
接下来我双管齐下
- 临时方案
- 加机器
- 当系统可用内存持续下降到特定临界值时,linux 系统会强制杀死耗用内存的进程——也就是我们的 jetty,所以让运维同学写了个脚本,定时检查 jetty 服务器状态,如果服务器挂了就及时拉起来
- 修改线上 nginx 配置,临时禁止对特定的接口访问
- 长期方案:全面优化
- 向测试部门提交压力测试申请,试图重现内存耗尽的场景
- 分析线上日志,找出性能不足和 pv 之间是否存在关联
- 分析线上日志,找出优化的目标
- 确定优化目标后,安排代码 review 和优化方案评审,通过评审以后进行版本开发和部署
- 对部分接口进行流控
优化
日志分析
日志分析的目的
- 告警和请求量/并发量之间是否存在关联
- 找出优化的目标
- 按请求量排序,优先优化请求量大的接口
- 按平均响应时间排序,优先优化响应慢的接口
日志分析的对象是 nginx 的 access log,主要使用 awk 命令
在分析日志时,我们犯了个错误,这导致我们初期优化目标没有指向问题成因——就像绝大多数项目的失败都可以从需求阶段找到原因一样,性能问题的解决,最关键的步骤就是原因分析阶段。
加机器
分析过日志后,发现告警和日 pv 貌似存在一定的相关性,和运维同学沟通后,决定增加机器,从最初的 3 台服务器,加到 5 台,然后加到 8 台,最后加到了 11 台机器
刚加完机器的几天,系统貌似消停了,但是就在你觉得可以睡个好觉时,告警短信又不期而至了
这也说明,性能问题不是简单的加机器可以解决的——如果机器的理论承载能力上限尚未实际达到,那么只能从程序里找原因。
流控
从日志里发现有个接口的 pv 巨大,占到了总 pv 的 70% 还多,这个接口是个应用更新信息接口,由客户端定时访问,功能是向客户端返回其已安装的应用是否存在新版本,并返回新版本的一些信息,诸如版本号,安装包大小,下载地址等
这个接口很难优化
- 平均每个用户安装的应用在 30——50 个之间,多的甚至有上百个,查询这些应用是否有最新版本的 SQL 语句很难优化
- 不同用户的安装列表不同,查询结果缓存后命中率很低
- 如果为每个用户的查询结果进行缓存,也比较困难
- 内存占用太大
- 用户的安装列表发生变化,或者应用信息发生更新,都会导致缓存数据的过期
为了解决问题,决定先对这个接口进行限流:让运维同学修改 nginx 配置,客户端访问这个接口时直接返回 200
修改 nginx 配置是临时方案,开发同学对这个接口进行流控,由于我们并未使用类似 sentinel 这类流控框架,所以只能由开发在代码里实现了:基本思路就是设定一个处理中的上限值,当上限值达到后,新的请求直接返回,示例如下
......
@Value("${appUpdate.maxSize}")
private int maxSize;
private final AtomicInteger realSize = new AtomicInteger(0);
......
{
int size = realSize.addAndGet(1);
try {
if (size <= maxSize) {
// 业务处理
......
} else {
// 直接返回
result.setReturnCode(BaseCode.SUCCESS);
}
} catch (Exception e) {
......
} finally {
realSize.decrementAndGet();
}
return result;
}后续又对其他几个接口进行了流控,流控的对象是用户无感的接口。
不过流控并没有解决我们的性能危机
压力测试
压力测试没有能重现内存耗尽的场景,但压力测试报告暴露了很多问题,指明了后续优化的方向,先看下第一期压测的报告,并未包括所有接口
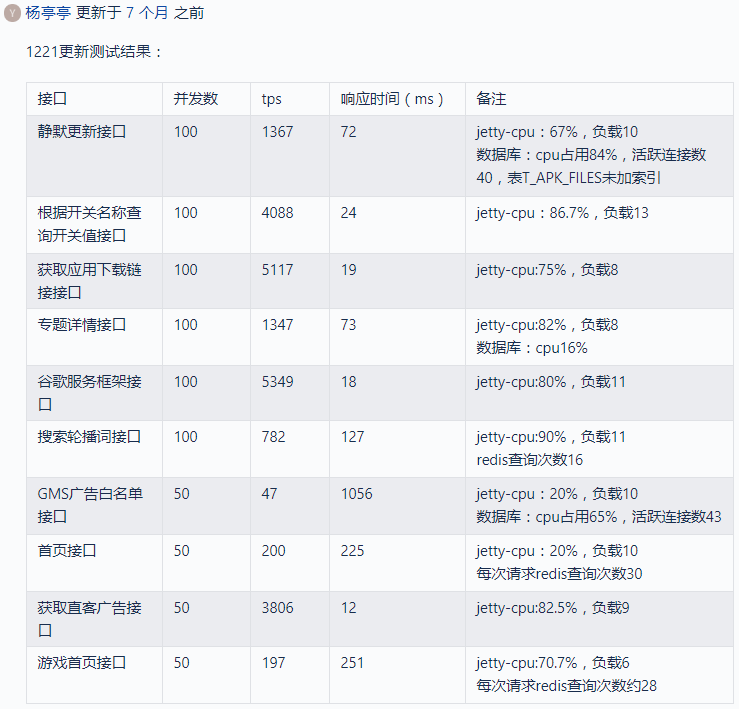
这个报告的信息量还比较大
- 我们的 TPS 普遍低下,个别接口更是低到发指
- 个别接口的实现逻辑有很大问题,例如首页接口需要查询 30 次 redis
- 某些查询没有用到索引
code review 和优化方案评审
基于日志分析的结果,后期还参考了压测报告,确定了一个要优化接口的清单,接下来的工作就是对每个接口重复以下工作
- 对该接口的代码进行评审,找出其中的问题
- 根据评审意见进行优化方案的设计
- 优化方案评审
- 代码实现
这里贴一下优化后的部分压测数据,虽然还是偏低,但对比最初的数据还是有比较大的提升的

利用 zabbix
虽然做了一些应该很有效果的工作,但是问题一直没有解决,告警来得还更猛烈了
这时候想起来公司 dba 团队有个 zabbix 监控系统,也许可以从中找到一点头绪。
从 zabbix 监控可以发现 2 个问题
伴随告警的发生,几乎必然会有一个 sql 慢查询的峰值
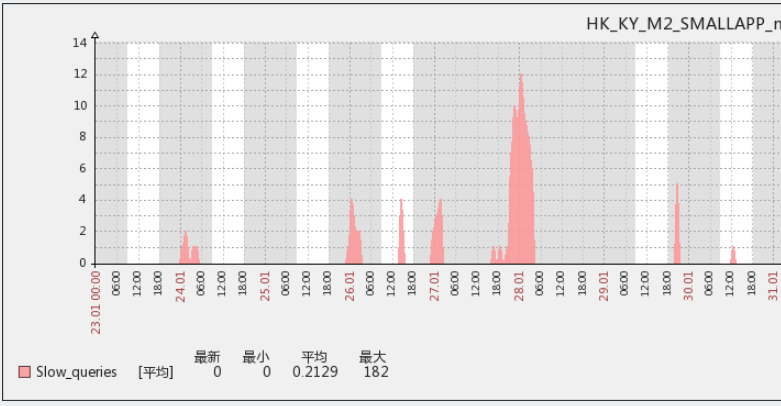
redis 的内存占用率一直很高

mysql 慢查询日志之前也找 dba 拿过,例如前面提到的应用更新信息接口,就是慢查询的大头
这个 redis 的内存占用还是比较奇怪的,我 review 了一些预热缓存的 task,发现个问题
SELECT
imei_sn_code
FROM
INSTALLED_RECORD
GROUP BY imei_sn_code这是一个预热用户已安装应用到 redis 的 task,所有向客户端返回应用列表的接口,都需要用到这里的数据来过滤掉该用户已经安装过的应用。
一般来说预热工作是不应该预热全量数据的,冷门数据命中率较低,是不应该预热的,所以判断哪些数据是热数据其实很重要,一个方法是统计用户行为,只预热活跃用户的数据;当然,如果数据量不大,简单粗暴的全量预热也不失为一个办法
这个 sql 从用户安装记录表中查询出所有用户,然后预热所有用户的安装列表。问题是这个表是后台最大的一张表,数据量在亿级别~!怪不得 redis 内存占用一直居高不下
紧急发布了一个版本,果然 redis 的内存占用立马就降下来了,但是性能问题并没有解决——问题不在这里
最终找到问题
zabbix 除了看 mysql 慢查询,还有个很有用的图表,可以看命令执行计数
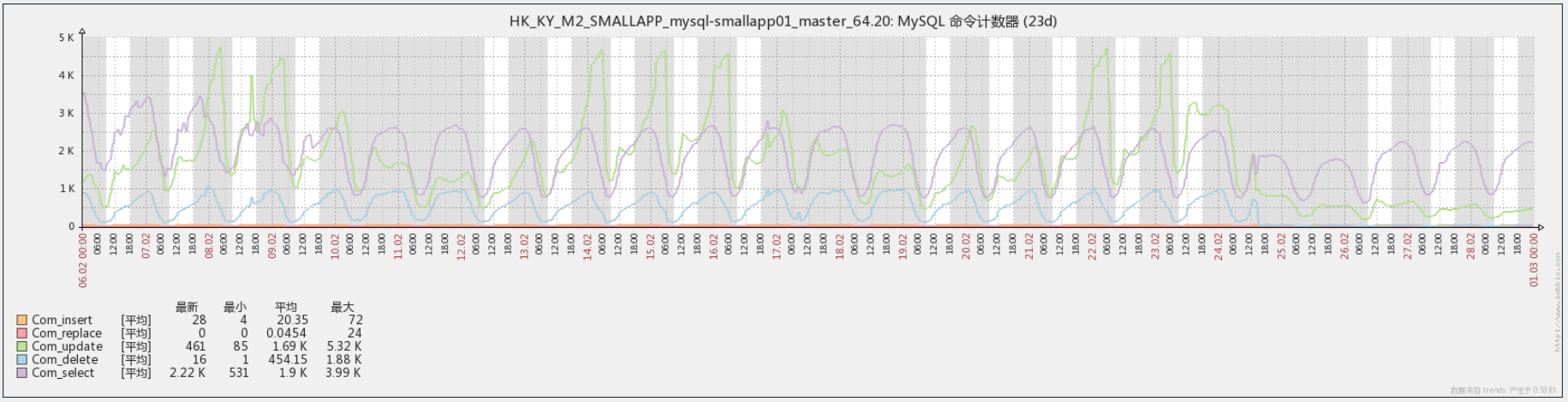
这个图里的 UPDATE 计数(绿色曲线)跟告警时间完美匹配,看来就是这个 update 在持续的引发告警
问题是这个 update 是神马业务?之前分析过 nginx 日志,除了个别访问量极小的接口,压根就没有哪个接口是需要做 update 操作的嘛
这时才发现,客户端有 3 个接口是用 https 协议调用的,这 3 个接口分别是应用安装、升级、卸载的上报。而之前分析 nginx 日志一直都忽略了 https 日志。
先要讲一下这个业务逻辑
- 当用户安装、卸载、升级(一个或多个)应用时,会触发客户端的上报
即使用户的操作不是通过我们的应用商店进行的,我们的应用商店也能通过系统通知得到信息,然后触发上报 - 也就是说,当一些超级应用升级时,会有一个上报的瞬时高峰
这种峰值和我们的日活峰值完全没有对应关系 - 如果上报失败,客户端会在下一次发起全量上报,即上报该用户已安装的所有应用
- 所谓下一次有 2 种场景
- 用户打开应用商店
- 下一次上报被触发
对这 3 个接口进行 review,问题也是多多,最主要的问题有 2 个
- 实现逻辑里有不必要的删除
例如用户上报一次安装,后台会先从安装记录表删除安装记录后再做插入,实际上这个删除操作通常都是做无用功,这条记录根本就不存在;程序猿的思路大概是担心用户以前安装过该应用,但是卸载时没有上报或者上报了但是后台没有正常处理 - 不正确的使用事务
用户上报是支持批量上报的,所以和全量上报实际上用的相同的代码,对于安装上报,后台处理逻辑是先删除后插入,这时用到事务倒也无可厚非。问题是后台代码在事务里还做了一件事——向大数据平台发送埋点数据,这会导致数据库事务不能及时释放
关于数据库事务,要快进快出,在事务里执行其他远程调用肯定是不应该的
针对 review 中发现的问题进行优化
- 不做删除,改为先 update,若 update 无效果再 insert
- 数据库事务提交以后,再发送埋点数据;后期取消了数据库事务
- 对这 3 个接口做流控
这个优化版本发布后,问题彻底解决,可以睡个好觉了
总结
告警原因
首先要说下我们的线上部署情况,最前端是 LVS 做负载均衡,LVS 后端的 RIP,是由该机器上的 nginx 反向代理给本机的 jetty——并不是一般意义上 nginx 做负载均衡的配置
告警原因当然是可用内存不足,达到了监控程序的阈值。那么可用内存为什么不足呢?
主要原因是部分业务接口响应太慢,而该接口上的请求却络绎不绝
线上机器的 jetty 工作线程配置是最大 1000 个,在业务高峰期,由于释放不及时,jetty 的工作线程会被这些慢请求全部占用
那么新来的请求会怎么办?这个我有空做个实验来验证下,暂时说下我的看法:新的请求 jetty 不会直接丢弃,而是进入一个排队队列,除非队列已满,或者进入排队以后超过了预期的等待时间,否则这个请求不会被丢弃
那么 nginx 相应的也要持有 jetty 正在处理和排队的请求,除非 nginx 等待 jetty 的应答超时
结果就是 jetty 和 nginx 同时持有大量请求等待处理,从而导致内存的大量被占用,直到监控程序发出告警
经验教训
- 分析 nginx 日志一定不要漏掉 https 日志
如果一开始就分析过 https 日志,应用安装上报接口肯定会进入优化目标的前列——它又慢,访问量又够大,可以肯定的说问题会更早解决 - 压力测试很难复现线上的问题
在线数据库的表里有亿级别的数据,压测不会准备这么多数据;另外,线上环境下,大数据平台会发生 RPC 调用超时,但压测环境下很难模拟出来 - zabbix 要好好利用起来
很多时候改 bug 也好,解决性能瓶颈也好,难点就在找到头绪——zabbix 是一个找到头绪的工具 - 代码质量
在开发人员技能水平有限,经验不足的情况下,要多组织技术分享、代码 review - 设计质量
很多代码确实实现了功能,但是实现逻辑简直没法看,这主要还是设计不良导致的
